
Google Tag Manager Server Side está en boca de todo marketer que se precie, pero esta herramienta no es fácil de entender: el etiquetado del lado del servidor genera muchas preguntas y no es sencillo encontrar información fiable que no sea tremendamente ambigua o tremendamente técnica. Este artículo pretende arrojar algo de luz sobre todas esas dudas y conseguir que cualquiera, aunque no tenga un background técnico, entienda qué es GTM Server Side, para qué sirve y, sobre todo, para qué no sirve.
El etiquetado en el servidor es una forma de instrumentar tus etiquetas para medir la actividad de los usuarios donde se produce. Los contenedores de servidor utilizan el modelo de etiquetas, activadores y variables que ya conoces y, además, ofrecen nuevas herramientas para:
- Mejorar el rendimiento de las páginas
- Acceder a controles de privacidad del usuario más detallados
- Mejorar la calidad de los datos
Pues está claro, ¿no? Vale, lo acabo de cortapegar de la documentación oficial de Google. Parece que cualquier artículo tipo «Google Tag Manager Server Side: qué es y para qué sirve» hay que empezarlo con una definición muy aburrida que no nos diga gran cosa, así que en este caso la he copiado directamente y así nos la quitamos de encima cuanto antes.
Pero bueno, yendo al grano, se trata de una versión de Tag Manager que se ejecuta sobre un servidor externo (a contratar aparte) en lugar de sobre el dispositivo del usuario, lo cual implica ciertas… ventajas e inconvenientes respecto a un setup más clásico, con el peso de la medición en el lado del cliente. ¿Cuáles? ¿Para qué sirve entonces? ¿Me conviene? Venga, vamos a la parte realmente interesante.
Índice del artículo
- ¿Para qué sirve realmente?
- ¿Sirve para sustituir al Tag Manager de toda la vida?
- ¿Sirve para reducir costes?
- ¿Sirve para mejorar el rendimiento de mi web o app?
- ¿Ayuda con las restricciones a cookies de terceros y ‘el futuro cookieless’?
- ¿Sirve para sortear Adblockers y otras restricciones?
- ¿Sirve para saltarse restricciones de consentimiento? ¿Ya no necesito aviso de cookies?
- ¿Sirve para obtener más volumen de datos de usuarios?
- ¿Sirve para mejorar la privacidad?
- ¿Sirve para mejorar la seguridad?
- ¿Sirve para integrar datos de otras plataformas?
- ¿Es necesario para integrar Facebook Conversions API o soluciones similares?
- ¿Puedo aprovechar una implementación client side que ya tenga?
- ¿Debería adoptar server side?
¿Para qué sirve realmente? O mejor dicho, ¿para qué ME sirve?
Aquí vendría la sección en la que nos ponemos a vender características y ventajas de forma un poco generíca y mezclada, y puede que quien venga buscando alguna duda o caso de uso concreto lo lea y se quede igual…
Así que vamos a intentar ser más específicos, repasar algunas de las situaciones que más habitualmente se mencionan e intentar dar respuestas directas y específicas a dudas y preguntas comunes, una por una.
¿Sirve para sustituir al Tag Manager de toda la vida? ¿Ya no lo necesito?
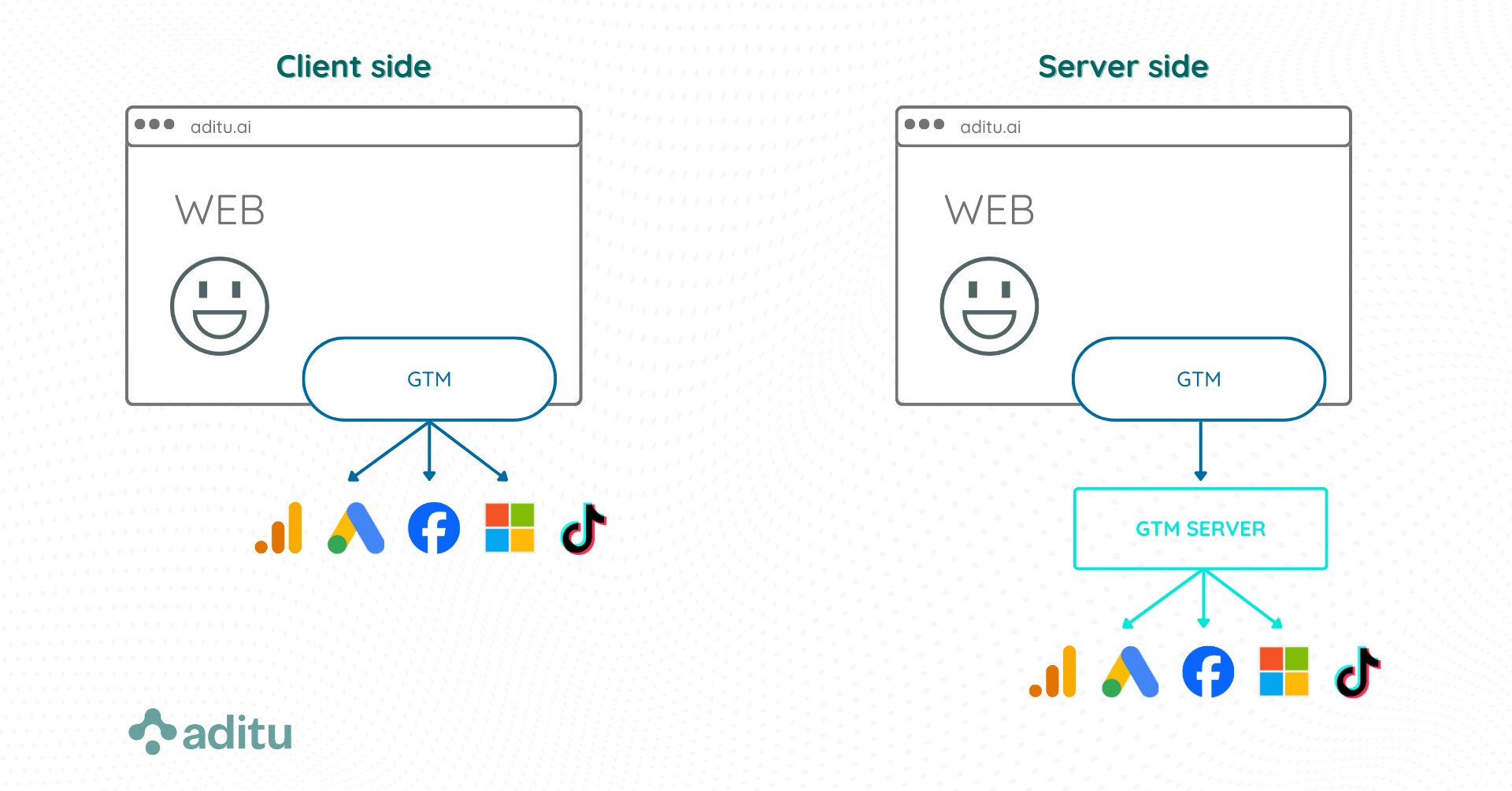
NO. Aunque en teoría podríamos crear un entorno server side puro, sería un caso complejo y muy poco probable. Lo normal será que convivan el contenedor server side con uno o más contenedores clásicos o client side.
No se sustituye nada, sino que se añade una capa adicional a la estructura habitual.
- El contenedor client side sigue encargándose de la funcionalidad necesaria en el lado del usuario: carga de scripts y etiquetas GA4, medición de interacciones, gestión de consentimiento… Pero en lugar de conectar directamente con los servidores de Google y demás proveedores, la única salida de datos es hacia el server side.
- El contenedor server side recibe este flujo de datos —y potencialmente los de otras fuentes adicionales— y es el que se encarga del procesado y envío final de información a cada servicio en el formato que corresponda.
¿Sirve para reducir costes?
NO. Al contrario, el coste y la complejidad va a ser inevitablemente mayor —pasamos de gestionar un set de etiquetas y configuraciones a dos—, así que debe ser un factor importante a considerar.
Además del coste puntual de la nueva implementación, debemos tener en cuenta:
- El coste recurrente de los servicios cloud necesarios para mantener funcionando el servicio.
- El coste de mantenimiento de la nueva —y más compleja— estructura.
- El mayor abanico de habilidades o perfiles necesarios para realizar este mantenimiento, incluidos conocimientos de sistemas, gestión de servicios cloud…
¿Sirve para mejorar el rendimiento de mi web o app?
SÍ. Dado que la mayor parte de la lógica, scripts y conexiones con servicios externos pasa a ejecutarse en nuestro servidor en lugar de en el dispositivo del usuario, esto se podrá traducir en mejoras en tiempos de carga y control de errores.
¿Ayuda con las restricciones a cookies de terceros y ‘el futuro cookieless’?
SÍ. Aunque la desaparición definitiva de las cookies third party o de sitios externos es un chicle que no para de estirarse y a estas alturas el inminente apocalipsis tampoco va a ser para tanto, está claro que esta es parte de la motivación de proveedores como Google para ofrecer soluciones server side como alternativas.
Si seguimos la configuración recomendada, de forma que tanto servidor ssGTM como sitio web compartan contexto y dominio principal, entonces por definición todas las cookies que se generen serán locales o first-party, y además de un tipo (cookies HTTP de servidor) al que se aplican en general menos restricciones por parte de mecanismos de protección como ITP de Apple.
Podemos incluso aprovechar el mayor control sobre las cookies generadas para reescribirlas o extenderlas y así mitigar también restricciones sobre cookies first-party.
¿Sirve para sortear Adblockers y otras restricciones?
PARCIALMENTE. En un setup server side correctamente configurado, todas las conexiones de datos en el lado del cliente saldrán hacia un servidor personalizado propio en lugar de a los diferentes —y fácilmente detectables— proveedores externos. Esto implica que serán bloqueadas con menos frecuencia por navegadores con adblockers o configuraciones avanzadas de privacidad, mejorando el volumen de datos recopilados.
Dicho esto, más allá de como posible optimización no deberíamos contar mucho con ello, al menos no como caso de uso principal. Si prolifera el uso de ssGTM como método de ofuscación de tracking, también lo hará el uso de filtros más avanzados (que pueden incluso empeorar las cosas al bloquear todo) para compensarlo. Siempre va a haber un cierto % de usuarios que no podamos —ni debamos— medir, y profundizar en esa carrera armamentística se vuelve progresivamente menos efectivo y más cuestionable.
Lo cual nos lleva a…
¿Sirve para saltarse restricciones de consentimiento? ¿Ya no necesito aviso de cookies?
NOOOO. Aquí no cambia nada. Las restricciones legales y éticas siguen intactas, y las técnicas también: la información y petición de consentimiento inicial (aviso de cookies y demás) debe seguir siendo gestionada y presentada del lado del cliente, las preferencias del usuario guardadas y respetadas, y cualquier señal recogida (ej. Consent Mode) propagada y tenida en cuenta en el lado del servidor.
¿Que podríamos aprovechar la opacidad que nos da el cambio de contexto para hacer cosas cuestionables a espaldas del usuario? Claro, como también podríamos hacerlo por otros medios o directamente pasarnos todo por el forro desde el principio y confiar en que nadie se de cuenta. Ta feo. Caca. Nope. Next.
Suscríbete a nuestra newsletter
Recibirás las últimas novedades del mundo de la analítica y de los datos directamente en tu buzón de correo.
¿Sirve para obtener más volumen de datos de usuarios?
PARCIALMENTE. Como ya hemos comentado, de algunos usuarios podremos llegar a tener más datos por el diferente comportamiento ante ciertas restricciones (ITP, bloqueos…). Así mismo, podremos tener datos de mayor calidad, pero no porque mágicamente aparezcan de la nada, sino porque tendremos más herramientas para integrarlos de distintas fuentes, combinarlos, filtrarlos, corregirlos… Antes de que salgan en dirección a Analytics y compañía.
Si el objetivo, sin embargo, es recuperar datos perdidos de usuarios que no aceptan cookies… Eso también está contestado ya: NO. Las preferencias del usuario y las señales de consentimiento deben respetarse exactamente igual que en cualquier otro tipo de setup. De nuestro lado queda interpretar el rechazo del usuario como aplicable a todo tipo de tracking o únicamente a cookies e identificadores de usuario (y permitir pings de seguimiento “anónimos”), pero para eso no necesitamos server side.
¿Sirve para mejorar la privacidad?
SÍ. A pesar de que cuando nos venden “la privacidad del usuario” suele ser como eufemismo de cómo saltársela —guiño, guiño— lo cierto es que en realidad ssGTM sí es una herramienta útil para mejorar la privacidad y la seguridad de datos sensibles, y más adecuada para eso que para lo contrario 😉.
La capa de filtrado adicional del server side nos proporciona un mayor control sobre los datos recopilados y la posibilidad de controlar exactamente qué información es la que sale en dirección a qué plataformas, evitar fugas de datos y envíos no autorizados de información protegida o personalmente identificable (PII).
Y sobre todo, al minimizar la ejecución directa de scripts de terceros en nuestras webs y apps, evitamos quedar a merced del buen funcionamiento y la buena fe de proveedores externos que puede que no gasten mucho de eso.

¿Sirve para mejorar la seguridad?
SÍ. Además de lo del mayor control sobre los datos que entran y salen, ocultar el contexto en el que ocurren ciertas operaciones protege contra posibles ataques o manipulaciones, y la simplificación de peticiones externas permite configuraciones de seguridad más estrictas en el servidor web.
¿Sirve para integrar datos de otras plataformas?
SÍ. De hecho, este es posiblemente el mejor caso de uso real para añadir una capa de server side.
Disponer de un punto de encuentro unificado, externo al entorno del usuario, entre los datos client side de navegadores y apps y los de otras fuentes externas como bases de datos de clientes, plataformas de ecommerce… y la posibilidad de combinarlos y enviarlos a la carta a Analytics y los proveedores externos que queramos, bien como eventos aparte (ej. conversiones offline) o enriqueciendo eventos existentes con información adicional extraída de nuestros CRM/CDP/ERP/CMS/OGT/demás plataformas internas de siglas poco pegadizas pero información valiosa 😀
Incluso sin datos extra que añadir, la sola posibilidad de enviar los mismos eventos y conversiones desde dos puntos distintos ya mejora la posibilidad de que se registren correctamente. Como en el caso de…
¿Es necesario para integrar Facebook Conversions API o soluciones similares?
NO. Es el método habitual y recomendado de implementación, pero no el único posible.
Este es un caso que estamos viendo muy a menudo. Meta pide muy insistentemente la integración de su nueva forma de medir conversiones más invasiva fiable, alguien sigue la documentación y crea un Server Side con una implementación a medida… solo para eso. Y el resto se deja igual. Y ahí se queda generando costes hasta que se rompa algo y no haya nadie para entrar a revisarlo, o llegue otro proveedor y te diga que qué hace eso ahí, oiga, que o contratamos mantenimiento o lo quitamos de enmedio, usted dirá.
Si esta es la única necesidad inmediata, existen soluciones alternativas (plugins, aplicaciones de terceros, integraciones externas…) que puede que impliquen menor coste y quebraderos de cabeza.
Otra cosa es que queramos aprovechar la excusa para dar el salto y crear una infraestructura más robusta y completa de cara al futuro… ¡pero entonces que no se quede ahí! El siguiente paso debería ser revisar y planificar cómo migrar todo lo demás…

Vale, pongamos que me lanzo. ¿Por dónde empiezo? ¿Puedo aprovechar una implementación client side que ya tenga? ¿O tengo que empezar de cero?
PARCIALMENTE. Probablemente se puedan reutilizar las etiquetas GA4 de una implementación existente (adaptándolas, eso sí, para que encajen en la nueva estructura), así como otros scripts auxiliares que deban seguir en el lado del cliente (ej. procesadores de eventos). El resto, idealmente, deberá reimplementarse en el lado del servidor si es posible.
En cualquier caso, un desarrollo nuevo (alta de infraestructura necesaria + implementación server side + adaptar/migrar lo necesario en el client side) será necesario sí o sí. Y mantenimiento posterior. ¿He mencionado ya lo del mantenimiento posterior? 🤓
¿En qué quedamos entonces? ¿Debería adoptar server side?
A estas alturas ya habrás podido adivinar que la respuesta es depende. Si después de leer todo lo anterior y analizado posibles casos de uso aún no lo tienes claro, es posible que no. O al menos, aún no. A pesar de llevar en funcionamiento desde 2020, se trata de un producto aún en fase de maduración, así que la adopción temprana no otorga tampoco una ventaja significativa. Si le unimos los inevitables costes adicionales que implica, “por si acaso” no es suficiente razón de peso.
Los siguientes casos de uso son, probablemente, buenas justificaciones para adoptar ssGTM a corto plazo:
- Mi inversión publicitaria es grande, lo suficiente para justificar por sí sola la optimización de su medición.
- Mi inversión o presupuesto en analítica es lo suficientemente grande para cubrir los costes adicionales y me interesa mantener una infraestructura sólida para afrontar con rapidez cualquier nueva necesidad y nuevos estándares de privacidad que posiblemente sigan apareciendo.
- Tengo un ecosistema complejo con datos de diversas fuentes ajenas a web y app (ej. conversiones offline, CRM, bases de datos externas) y quiero integrar toda esta información para su consumo en Analytics, BigQuery, dashboards…
- La seguridad y privacidad de los datos es MUY importante en mi organización, y debo asegurar el máximo control sobre los mismos (evitar leaks, envío de PII, etc.).
Por otro lado, puede que no necesites ssGTM o no sea (aún) suficiente justificación si tus motivaciones son:
- Quiero saltarme adblockers.
- Quiero saltarme restricciones de consentimiento.
- Meta o alguna otra plataforma publicitaria me lo pide para su seguimiento (ej. Facebook CAPI) y no tengo planes de usarlo para nada más.
- Tengo cualquier otra necesidad o justificación para hacer la implementación, pero no los recursos para mantenerla posteriormente.
Lo que está claro es que es una herramienta cuya presencia no podemos ignorar. Salvo repentino bandazo de Google y que le diera por abandonarlo a su suerte en favor de otras soluciones (caso aparentemente improbable para sus intereses pero que nunca podemos descartar), todo parece indicar que a largo plazo la adopción será generalizada, y tarde o temprano cualquier setup de analítica suficientemente maduro considere integrarlo entre sus soluciones.
Pero que parezca algo casi inevitable no significa que sea urgente. No estamos ante un caso de migración obligatoria como GA4 o Consent Mode. En este caso no vemos ventajas en la adopción inmediata si no está primero justificada. Y sin la planificación e inversión adecuada, mantenimiento posterior incluido, puede resultar incluso contraproducente.


Gran gran artículo Aitor! 🔝
Instructivo y divertido.
Ok!